
🏘️ Run over 120+ NPCs, in a tiny AI town with RWKV
Small tiny models, are all you need for NPC chat

If you needed proof that AI models, will play a major future in gaming, look no further.

Github repo is here: https://github.com/recursal/ai-town-rwkv-proxy
Working together with the AI town team @ a16z - we have fine-tuned a tiny, highly efficient RWKV 3B and 1.5B model, for the purpose of AI town use cases. All running locally on a macbook pro.
This has exciting potential both for gaming industry as a large, where we can simulate a large number of NPCs, with believable character chatter.
However what was more exciting to the team here at recursal, was the process behind it, as the impact extends beyond gaming.
As this can be replicated on any existing AI agents deployment, while taking advantage of RWKV lower cost advantages.
Where it is able to run on less then 1/10th the cost of existing GPT3.5 models pricing (with more potential to go lower).
Automated distillation with Recursal
The above AI town model was distilled from the original AI agent usage of Open AI, with a process that can be fully automated.

Our team didn’t need to build the dataset required for the fine tune by hand. All we simply did was collect the required data by using a proxy in between the AI agents and the OpenAI backend.
Using the data collected, we then fine-tuned a model respectively, and slowly begun offloading requests to the our RWKV optimized model.
While at the beginning the RWKV model may not be able to cover all use cases, overtime as the dataset is being built up, the model is incrementally finetuned to cover a wider array of capabilities.
Effectively, allowing drastic reduction in OpenAI 3.5 / 4 bills, at no performance compromises.
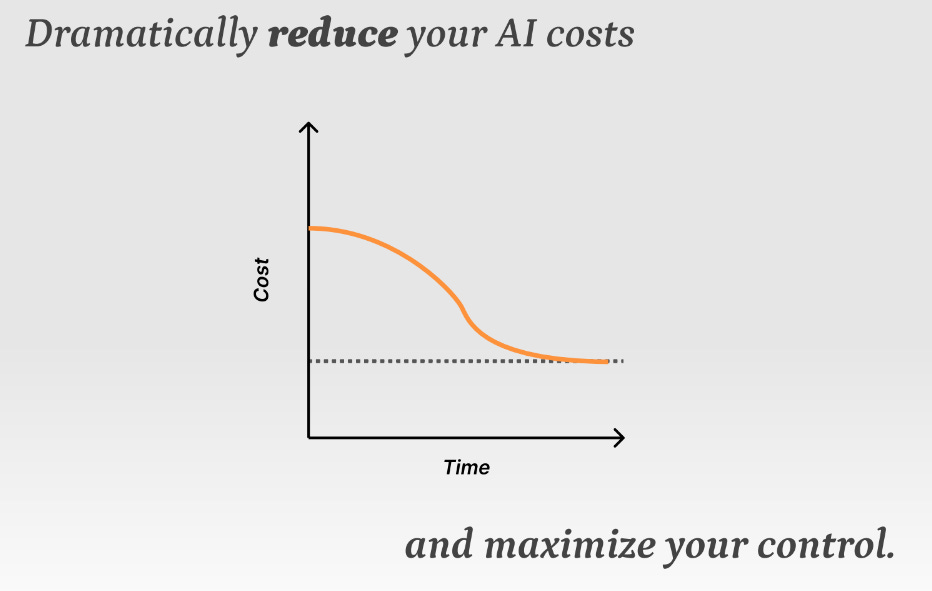
This process is not new, in itself, and is commonly known as AI distillation.
However what is new is the usage of
Automated processes to simplify the distillation process, and dataset cleaning.
Usage of smaller / more efficient RWKV models in the process, previous industry attempts at distilling LLaMA2 70B models, has proven to be not price competitive
The usage of a smaller model in the router, to decide which requests gets to be routed to the RWKV model, and the openAI platform
All of which would be the focus for our upcoming recursal AI platform launch. Of which we would kick start our closed beta by Mid-December.
If the above process excites you, on the potential of drastic cost savings on your existing AI work load, you can signup for our closed beta pilot at the following form.
https://docs.google.com/forms/d/e/1FAIpQLSekNp_npm7unSmlfWsUsGs3aaBrplgKE8sLiHLoyeJaqvj5bQ/viewform
 | A guest post by
|