
Model Support Summary + new this week
Nemo 12B and Qwen2 32B latest additions for a total of 12 model families

Featherless is a new kind of inference provider: we are building serverless inference for all of hugging face. We’re working through this one architecture at a time (e.g. Llama 3.1 8B).
Since our initial launch in June, we’ve been adding architectures, with fanfare only in our discord. But with Mistral Nemo 12B and Qwen2 32B becoming supported this week, taking the # of supported architectures to 12 and the total inferencible model count* to nearly 2k (1,922 at time of writing), this post seems overdue.
The full list of supported architectures is available on our about page, but the timeline is this
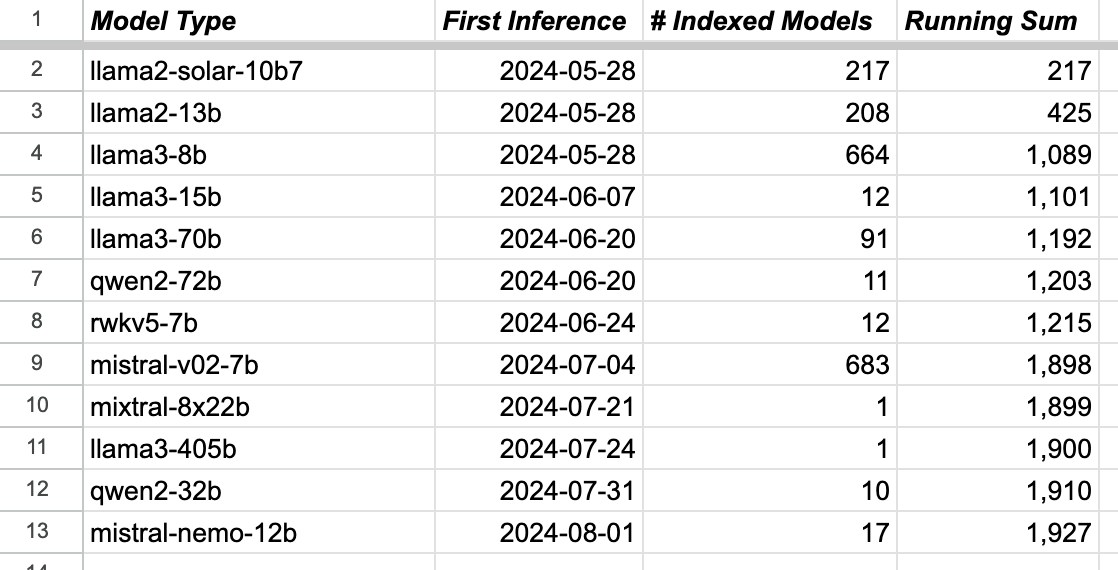
When you break that model registration out over time, it looks something like this

That smaller models are easier (take less time and money) to fine-tune accounts for a larger proportion of 7B and 8Bs (versus 70B, 72B). Likewise the older the model is, the more time folks have had to fine tune (hence many Llama 2 tunes, but few Nemos and Qwens).
If you want to weigh in on what model architecture we’re supporting next, join our discord.
Also a plug for fine-tuners: we’re working on a set of features that will be of benefit to model creators. If you are doing some fine-tuning, we’d love to connect with you for feedback on these upcoming features.