
Featherless: an introduction
making every hugging face model available for inference and why it matters

There’s a custom model for that
There are more than 100,000 distinct language models on the hugging face hub.
This is the output of an enormous amount of creative energy: built by over 10k AI enthusiasts, these models include impressive attempts to improve upon the best known language models like ChatGPT.
A lot of airtime goes to innovations on technical elements of language models (e.g. context length). And while important, that a huge part of what left with a collection there are a great many of domain specific LLMs like
for specific languages (e.g. for German, Russian or Chinese)
for creative-writing (e.g tdrussell’s Llama-3-70b-Instruct-Storywriter)
with detailed medical knowledge (e.g. BioMistral/BioMistral-7B)
can understand SEC filings, (e.g. arcee-ai/Llama-3-SEC)
legal (e.g. umarbutler/open-australian-legal-llm - a model trained on a dataset of Australian Law curated by the Australian Attorney General’s office!)
novelty / character (e.g. MopeyMule)
but it’s hard to use
So how do you use these things?
Despite that HuggingFace is the defacto place to host models, you’re hard pressed to use them there. If you’ve spent time on the site, you may have forgotten that there is a specific part of the model card designed to let you test the model: it’s typically disabled for models 8B and up, which is the vast majority of models.
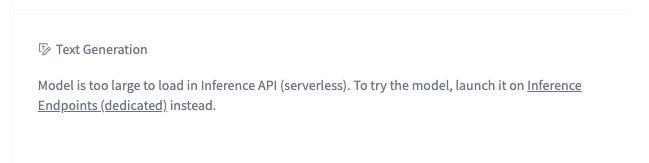
This kind of UX is a fact of that running these models requires operating expensive hardware (i.e. GPUs). You can rent these GPUs, but you’re looking at at least $2 / hour, and that would only cover you for the smaller models.
If you have a budget to experiment with, you can try launching the model on a dedicated service. However this will also require your patience; the most natural service to do this is HuggingFace’s inference endpoints service. Which I haven’t gotten it to work, despite the suggestion I should be able to launch a model in a few clicks.
Openrouter is probably the cloud service with the most options and offers per-token pricing. but it doesn’t have any of the models listed above. Nor does it let you bring your own model.
You can try and run it locally (and there are a host of tools that have significantly simplify the process - gpt4all, ollama and cortex are the more popular. But they still require technical orientation, patience, and, most importantly, powerful computing hardware.
Experiment Faster with Featherless
The goal of featherless is to make every LLM on hugging face available serverlessly. Right now, our collection is up to 1,501 models, making it the largest collection of models available for inference from any inference provider.
You can test any of the models on the site, but we’re expecting that you’ll plug this directly into a client, whether that’s to chat with it as a human e.g. via Typing Mind, Jan, or Silly Tavern, or you’ll use the API directly, e.g. in a raw python program, or in some higher-level framework like Lang Chain or Llama Index
Checkout our terms of service and privacy policy.